| 【深度学习】模型压缩(MobileNet系列、蒸馏、量化) | 您所在的位置:网站首页 › 模型压缩 量化 › 【深度学习】模型压缩(MobileNet系列、蒸馏、量化) |
【深度学习】模型压缩(MobileNet系列、蒸馏、量化)
|
深度学习模型压缩(MobileNet系列、蒸馏、量化)
模型要在边缘端计算,需要具有较小的内存、计算和带宽需求,一般通过设计轻量化的架构或者对模型进行蒸馏、剪枝和量化等来减少参数,获取高效的模型。 本文简要介绍轻量化架构(以 MobileNet V1 和 MobileNet V2 为例)、蒸馏和量化方法。 1.轻量架构(Light-weight architecture)从卷积核、特殊层和网络结构等方面设计轻量网络 以MobileNet为例 MobileNet V1[1] Depthwise Conv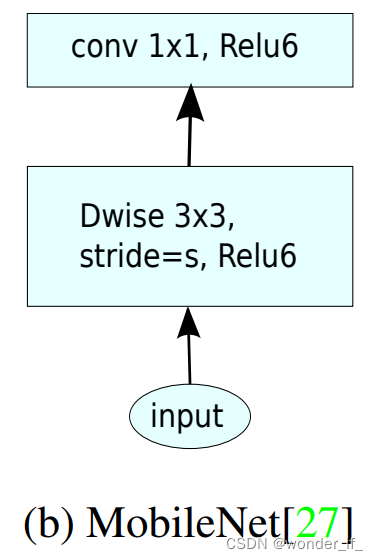 图1. 深度可分离的滤波器:(a)中的标准卷积滤波器被两层所取代:(b)中的深度卷积和(c)中的点卷积。普通卷积:
(
d
k
⋅
d
k
)
⋅
c
i
n
p
u
t
⋅
c
o
u
t
p
u
t
(d_k \cdot d_k) \cdot c_{input} \cdot c_{output}
(dk⋅dk)⋅cinput⋅coutput深度可分离卷积:
(
d
k
⋅
d
k
)
⋅
c
i
n
p
u
t
+
(
1
×
1
)
⋅
c
i
n
p
u
t
⋅
c
o
u
t
p
u
t
(d_k \cdot d_k) \cdot c_{input} + (1 \times 1) \cdot c_{input} \cdot c_{output}
(dk⋅dk)⋅cinput+(1×1)⋅cinput⋅coutput Width Multipler:减少卷积核个数 MobileNet V2[2]
Inverted Residuals 图1. 深度可分离的滤波器:(a)中的标准卷积滤波器被两层所取代:(b)中的深度卷积和(c)中的点卷积。普通卷积:
(
d
k
⋅
d
k
)
⋅
c
i
n
p
u
t
⋅
c
o
u
t
p
u
t
(d_k \cdot d_k) \cdot c_{input} \cdot c_{output}
(dk⋅dk)⋅cinput⋅coutput深度可分离卷积:
(
d
k
⋅
d
k
)
⋅
c
i
n
p
u
t
+
(
1
×
1
)
⋅
c
i
n
p
u
t
⋅
c
o
u
t
p
u
t
(d_k \cdot d_k) \cdot c_{input} + (1 \times 1) \cdot c_{input} \cdot c_{output}
(dk⋅dk)⋅cinput+(1×1)⋅cinput⋅coutput Width Multipler:减少卷积核个数 MobileNet V2[2]
Inverted Residuals
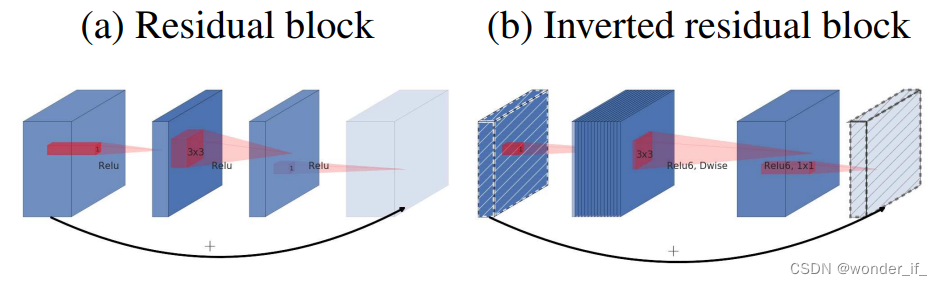 图2. 残差块[8,30]和倒残差的区别。有对角线阴影的层不使用非线性激活函数。我们用每个块的厚度来表示它的相对通道数。注意经典的残差连接的是通道数量多的层,而倒残差则连接瓶颈层。 Linear Bottleneck
作者通过实验发现ReLU激活函数对低维特征造成大量损失,由于倒残差结构是“两头细中间粗”的结构,所以输出的时候是一个低维的特征。为了避免信息的丢失我们就需要使用一个线性的激活函数替代ReLU激活函数。 图2. 残差块[8,30]和倒残差的区别。有对角线阴影的层不使用非线性激活函数。我们用每个块的厚度来表示它的相对通道数。注意经典的残差连接的是通道数量多的层,而倒残差则连接瓶颈层。 Linear Bottleneck
作者通过实验发现ReLU激活函数对低维特征造成大量损失,由于倒残差结构是“两头细中间粗”的结构,所以输出的时候是一个低维的特征。为了避免信息的丢失我们就需要使用一个线性的激活函数替代ReLU激活函数。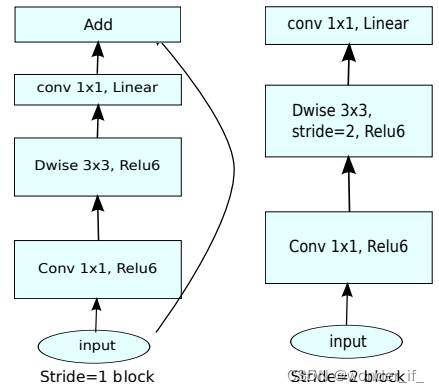  左图:不同stride下的残差结构;右图:Bottleneck residual block ,其中,通道从
k
k
k 到
k
′
k'
k′ , stride为
s
s
s, 扩张因子为
t
t
t architecture 左图:不同stride下的残差结构;右图:Bottleneck residual block ,其中,通道从
k
k
k 到
k
′
k'
k′ , stride为
s
s
s, 扩张因子为
t
t
t architecture
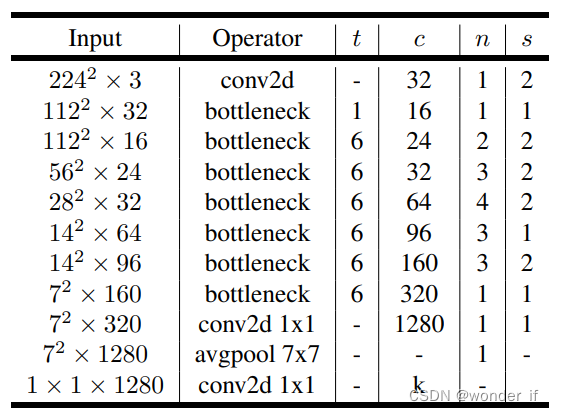
类似的工作还有ShuffleNet V1, ShuffleNet V2, MobileNetV3以及GhostNet等 2. 蒸馏(Distillation)知识蒸馏(Knowledge Distilling)是模型压缩的一种方法,是指利用已经训练的一个较复杂的Teacher模型,指导一个较轻量的Student模型训练,从而在减小模型大小和计算资源的同时,尽量保持原Teacher模型的准确率的方法。 这种方法受到大家的注意,主要是由于Hinton的论文Distilling the Knowledge in a Neural Network |
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |